How to make Surprise 10x faster
In July 2021 I had to build a basic web app to recommend movies to a user based on past preferences. The project introduced me to many Python packages, including the topic of this post: Surprise1.
Surprise is a Python scikit for building and analyzing recommender systems that deal with explicit rating data.
Surprise implements various recommender algorithms, including SVD, SVDpp, and NMF (known as Matrix factorization algorithms). We'll mainly be looking at SVD and SVDpp in this post.
During the course of my project I ran into some performance issues, which I'll first clarify using some benchmarks, then I'll show you how I solved those issues.
Benchmarks
The table below illustrates (among other things) the total execution time of our 3 target algorithms, as tested by one of the original authors 2.
All experiments are run on a notebook with Intel Core i5 7th gen (2.5 GHz) and 8GB RAM.
The Time will probably be a bit lower on more modern hardware, but the problems remain and the optimisations are still effective.
| MovieLens 100k | RMSE | MAE | Time |
|---|---|---|---|
| SVD | 0.934 | 0.737 | 0:00:11 |
| SVD++ | 0.92 | 0.722 | 0:09:03 |
| NMF | 0.963 | 0.758 | 0:00:15 |
| MovieLens 1M | |||
| SVD | 0.873 | 0.686 | 0:02:13 |
| SVD++ | 0.862 | 0.673 | 2:54:19 |
| NMF | 0.916 | 0.724 | 0:02:31 |
SVDpp produces the lowest RMSE (it's the most accurate in a sense), but based on the execution Time it's practically unusable in any real-world context.
A bit of context will make it abundantly clear why that's the case:
-
MovieLens 1M is a dataset of roughly 1 million ratings, from 6000 users on 4000 movies.
-
Netflix has about 222 million total subscribers and almost 6'000 titles in its US library alone.
Clearly SVDpp is not going to cut it on any real-world dataset (in its current state).
That begs the question, how do we make Surprise run faster?
First we need to learn about something called Cython (C + Python?).
Cython
Cython is an optimising static compiler for both the Python programming language and the extended Cython programming language (based on Pyrex). It makes writing C extensions for Python as easy as Python itself.
...
The Cython language is a superset of the Python language that additionally supports calling C functions and declaring C types on variables and class attributes. This allows the compiler to generate very efficient C code from Cython code.
Cython is amazing (even though I didn't know it existed until 6 months ago). I encourage anyone who hasn't heard of (or worked with) Cython to play around with it, since I'm just going to glance over most of it.
I will, however, include a snippet of an official Cython tutorial:
The Basics of Cython:
The fundamental nature of Cython can be summed up as follows: Cython is Python with C data types.
Cython is Python: Almost any piece of Python code is also valid Cython code. (There are a few Limitations, but this approximation will serve for now.) The Cython compiler will convert it into C code which makes equivalent calls to the Python/C API.
But Cython is much more than that, because parameters and variables can be declared to have C data types. Code which manipulates Python values and C values can be freely intermixed, with conversions occurring automatically wherever possible. Reference count maintenance and error checking of Python operations is also automatic, and the full power of Python’s exception handling facilities, including the try-except and try-finally statements, is available to you – even in the midst of manipulating C data.
(the highlighted section is important in a bit)
Why is SVDpp so much slower than SVD?
I wondered the same thing.
Both SVD and SVDpp are algorithms that consider explicit ratings by users on items.
What differentiates SVDpp from SVD is the fact that SVDpp also considers implicit ratings.
This means SVDpp considers a lot more data.
From the Wikipedia article on recommender systems
Explicit data collection includes the following:
- Asking a user to
- rate an item on a sliding scale
- search for something
- rank a collection of items from favorite to least favorite
- Presenting two items to a user and asking him/her to choose the better one of them.
- Asking a user to create a list of items that he/she likes (see Rocchio classification or other similar techniques).
Implicit data collection includes the following:
- Observing the items that a user views in an online store.
- Analyzing item/user viewing times.
- Keeping a record of the items that a user purchases online.
- Obtaining a list of items that a user has listened to or watched on his/her computer.
- Analyzing the user's social network and discovering similar likes and dislikes.
The Surprise implementations
If you take a look at the matrix_factorization.pyx (notice the *.pyx extension?) file in the Surprise source you can read through the implementations of SVD, SVDpp, and NMF (if you want).
A commonality between all 3 algorithms is the start of the training loop:
for current_epoch in range(self.n_epochs):
for u, i, r in trainset.all_ratings():
It boils down to: loop n_epochs (by default 20 for SVD and SVDpp, 50 for NMF) times through all of our training data.
In the MovieLens 1M case that's over 1 million data points!
This primary training loop is where any optimizations would make the most difference. Let's get started!
Running our own benchmarks
First we'll create a new benchmark script that tests only the 3 algorithms we're interested in. You can find the benchmark script here.
Running this benchmark on my machine produces the following table (only including algorithms found in the matrix_factorization.pyx file):
| Movielens 100k | RMSE | MAE | Time |
|---|---|---|---|
| SVD | 0.936 | 0.738 | 0:00:12 |
| SVD++ | 0.922 | 0.723 | 0:07:08 |
| NMF | 0.964 | 0.758 | 0:00:11 |
This will be our starting point. Now how exactly do we optimise this?
Cython annotated output
Remember the highlighted section I said would be important?
Code which manipulates Python values and C values can be freely intermixed
This freely intermix-able nature of Cython is exactly where our Surprise problem comes from! As a rule, Python is slow and C is fast. Whenever Python objects and Python’s C-API interact there's a bottleneck.
Luckily for us, Cython has a way to visualize where interaction with Python objects and Python’s C-API take place - allowing us to visualize where our algorithm might be slowing down.
How do we do that?
Using cython -a -3 <filename>.pyx on any *.pyx file.
The
-3tells Cython to use Python 3 syntax.
This command produces an annotated file for us to explore. Since this isn't really a follow-along, I've already generated such a file for the matrix_factorization.pyx code we're looking at. You can access it here.
Right at the top you should see an explanation of what you're looking at:
Yellow lines hint at Python interaction.
Click on a line that starts with a "+" to see the C code that Cython generated for it.
Let's start by taking a look at SVDpp, since it's the slowest (by-far).
Scroll down to line 444, you should see this:

Don't worry about the specifics of what the code is doing, just know it's doing something and there is a massive amount of yellow lines! The yellowness indicates the amount of Python interaction.
Feel free to play around with this file, if you expand too much, and it starts getting overwhelming just refresh the page.
Optimizing Cython code
Now we get to the real reason behind this post: making Cython code faster. Specifically, making the generated C code interact with Python as little as possible (at least in the performance critical sections).
Phase 1: Loops
First I got rid of all the Python for loops, replacing them with Cython while loops.
Basically I changed this
for f in range(self.n_factors):
u_impl_fdb[f] += yj[j, f] / sqrt_Iu
into this
f = 0
while f < facts:
u_impl_fdb[f] += yj[j, f] * sqrt_Iu
f += 1
in a few places.
(the for in range construct is known as a for each loop)
I then added some C++ data structures (vector and map to be specific) to allow me to pre-compute some values before the training loop.
Phase 2: Pre-compute
If you look back at the original code, specifically line 451, you'll notice this code:
sqrt_Iu = np.sqrt(len(Iu))
We're taking the square-root of the length of our user-item list, since this is inside the training loop we repeat 20 - 50 times we're redoing the same calculation a bunch of times. Additionally, the line is very yellow.
To fix this, and a few other things I added the following code to pre-compute some stuff before the training loop:
# some c++ maps mapping int (user id, to a list of liked id's)
cdef mapcpp[int, vectorcpp[int]] Iu_items
# map to store pre-calculations that don't need to be repeated
cdef mapcpp[int, double] Iu_len_sqrts
# fill our item list, using normal python for-loops is fine
# since we're outside of our training loop
for i in range(trainset.n_users):
for j, _ in trainset.ur[i]:
Iu_items[i].push_back(j)
# define an iterator iterating over our user items map from before
cdef mapcpp[int, vectorcpp[int]].iterator it = Iu_items.begin()
# here we pre-compute those pesky square roots
# we take the inverse of sqrt to allow us to multiply
# inside the training loop, instead of dividing - this is faster
while(it != Iu_items.end()):
Iu_len_sqrts[dereference(it).first] = 1.0 / np.sqrt(dereference(it).second.size())
postincrement(it)
# declare facts as a c variable, so we reduce C / Python interaction in the loop
cdef int facts = self.n_factors
cdef double err_qif_sqrt = 0.0
Intermission
Now the training loop looks like this:
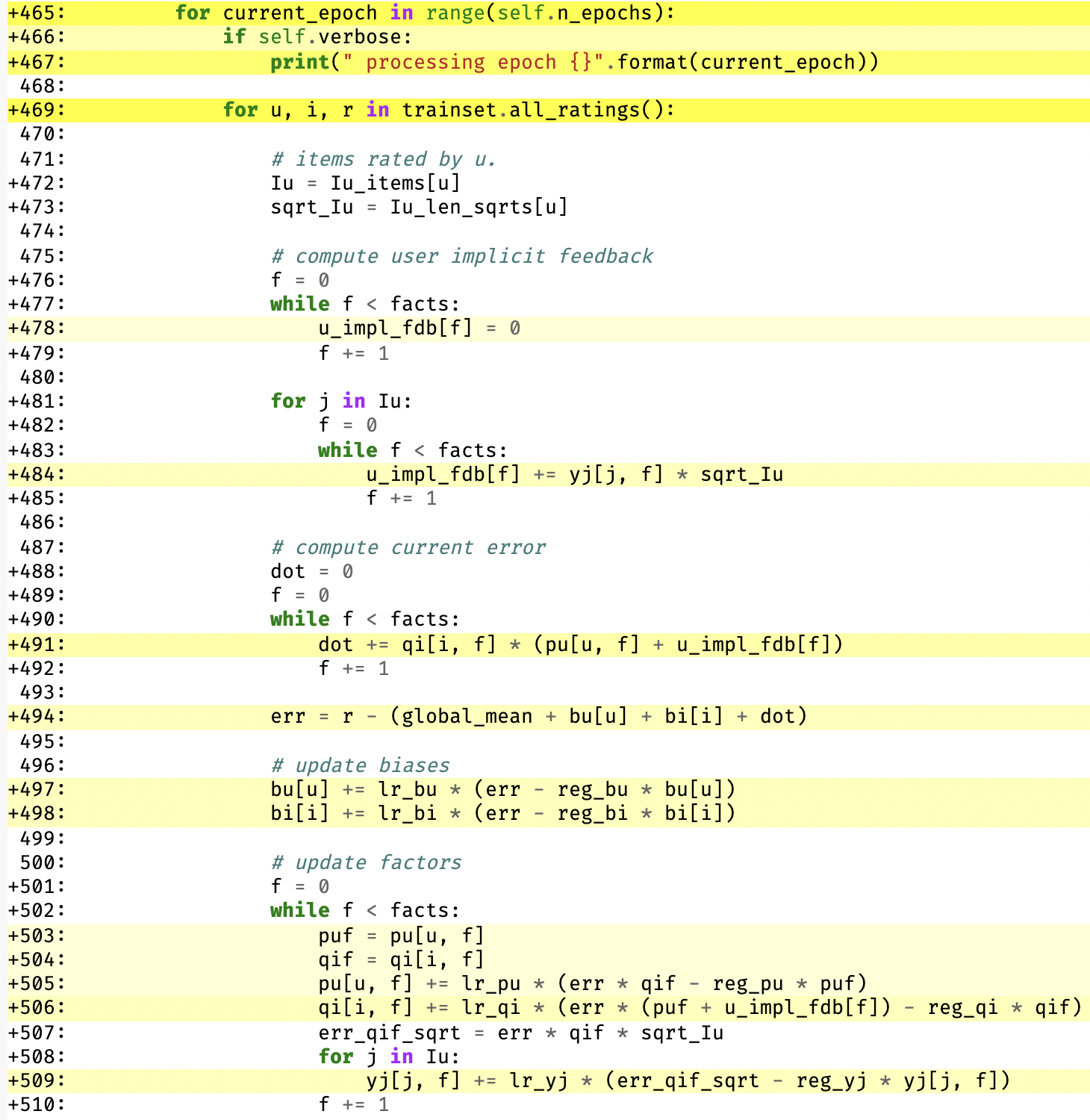
Significantly less yellow! You can find the annotated Cython output for this code here.
To gain access to some of those C++ data structures, I added the following imports to the top of the file:
from libcpp.map cimport map as mapcpp
from libcpp.vector cimport vector as vectorcpp
from cython.operator import dereference, postincrement
I also had to add language="c++" to setup.py, so that Cython would compile C++ code (since I used the aforementioned C++ data structures).
You can check out the git commit with everything that's changed up to this point (if you're curious).
If we now run the same examples/bench_mf.py as before we get:
| Movielens 100k | RMSE | MAE | Time |
|---|---|---|---|
| SVD | 0.936 | 0.738 | 0:00:12 |
| SVD++ | 0.922 | 0.723 | 0:01:12 |
| NMF | 0.964 | 0.758 | 0:00:11 |
A HUGE improvement - SVDpp is now roughly 6.3x faster!
We can apply similar optimisations to the SVD code and run the benchmark again:
| Movielens 100k | RMSE | MAE | Time |
|---|---|---|---|
| SVD | 0.936 | 0.738 | 0:00:03 |
| SVD++ | 0.922 | 0.723 | 0:01:12 |
| NMF | 0.964 | 0.758 | 0:00:11 |
A roughly 4x increase in speed for SVD. Excellent! Those little Python interactions cost us quite a bit of performance.
Phase 3: Bounds Checking & Negative Indexing
I did promise 10x faster though, currently we're only up to 6.3x, what gives?
There is one more slight change we can make that has massive performance implications.
Did you notice in the training loop most of our code still has a slight yellow tint?
That's thanks to a handy feature known as bounds checking in numpy arrays. Basically, Cython adds some code to ensure we're not accessing parts of the array that don't exist (say the 11th element of a 10 element list).
Another neat feature is negative indexing (when you access the last element in a list using list[-1], for example, you're doing negative indexing).
See the official Cython docs for more details.
Both of these checks are helpful in some cases, but we are certain of 2 things:
- Our code always accesses the numpy arrays in-bounds.
- We never use negative indexing.
Therefore, we can explicitly disable these features by adding the following code:
@cython.boundscheck(False) # Deactivate bounds checking
@cython.wraparound(False) # Deactivate negative indexing.
def sdg(self, trainset):
... # rest of sdg function
This is the final annotated output with all our changes, feel free to compare it to where we started.
Results
With these final optimizations in place, we can run the examples/bench_mf.py script again to see the fruits of our labour:
| Movielens 100k | RMSE | MAE | Time |
|---|---|---|---|
| SVD | 0.936 | 0.738 | 0:00:02 |
| SVD++ | 0.922 | 0.723 | 0:00:32 |
| NMF | 0.964 | 0.758 | 0:00:11 |
As promised, 10x faster! In fact, 32 seconds compared to 7 minutes and 8 seconds back when we first started is 13.38x faster, under-promise & over-deliver. SVD also improved from 3 seconds to 2, a 6x improvement over the original).
(As an exercise to the reader, try to optimise NMF in the same way I optimised SVD and SVDpp - by removing those Python C-API interactions)
The final commit is available here, you can also compare my fork with the original Surprise source to see all the changes made in this article.
Conclusion
In this post I briefly described a performance issue I faced using Surprise, and how I solved it.
In the end I improved the total running time by more than 13x for SVDpp, and about 6x for SVD.
Throughout this process the Cython documentation was incredibly helpful, I learned a lot by reading through the tutorials.
We can run the examples/bench_mf.py script one last time using the MovieLens 1M dataset, to produce a final benchmark:
| Movielens 1M | RMSE | MAE | Time |
|---|---|---|---|
| SVD | 0.874 | 0.686 | 0:00:30 |
| SVD++ | 0.862 | 0.672 | 0:10:46 |
| NMF | 0.917 | 0.725 | 0:01:53 |
SVDpp, which previously took almost 3 hours (granted, outdated benchmarks; it'd probably take around 2 hours on my machine), now runs in under 11 minutes!
Installing the fork
If you'd like to use the updated Surprise in your projects, simply run:
pip install git+https://github.com/ProfHercules/Surprise
(no breaking changes were made, so it should "just work")
You can track the status of the pull request (to merge the optimised code into the official Surprise codebase here).
I hope you enjoyed the post - happy learning!
Footnotes
The Surprise documentation is an excellent resource for anyone seeking to understand the technical details behind recommender algorithms, and possible implementations thereof, in more detail.
Full original tables can be found here.